I’m not sure why it didn’t exist before, but given the events of the past month I’m utterly shocked that neither WordPress, Automattic, nor the community have built an importer to allow people to easily put their Facebook data export into a WordPress website.
There was a time in the early days of social media that I signed up for every service that came out. The username @spigot is mine across most services you can find. By the time Instagram started, I’d started to grow weary and standoffish to new services. I’m sure you know what I mean. So I held ...
What is your favorite site that’s disappeared? What’s your favorite 404 page? What site do you think will disappear before we celebrate 404 again next April 04?
Wish Twitter would distinguish between "favorite" and "save for later." People could infer some pretty misleading things...
Intent on Twitter is often so muddled, this is the last thing some might worry about. (Yet it’s still a tremendous tool.) Pocket has browser extensions, and I know the one for Chrome has settings one can toggle an icon to appear on Twitter to allow bookmarking things to read for later directly within your Pocket account, which is generally a reasonable experience.
Pocket’s browser extension can add a much better “save to read for later” button to one’s Twitter feed.
I think the much stronger and better solution for one’s personal commonplace book is to simply add these intents to one’s own website and either favorite, bookmark, mark as read, repost, reply to, annotate, highlight, or just about “anything else” them there and syndicate the appropriate response to Twitter separately. (Examples: bookmarks and reads.) This makes it much more difficult to muddle the intent. It’ll also give you a much more highly searchable set of data that you can own on your own website.
Why wait around for Twitter or another social service to build the tools you want/need when it’s relatively easy to cobble them together for yourself on a variety of opensource platforms? While you’re at it, remove some of the other limitations like 280 characters as well…
There’s so much great material out there to read and not nearly enough time. The question becomes: “How to best organize it all, so you can read even more?”
I just came across a tweet from Michael Nielsen about the topic, which is far deeper than even a few tweets could do justice to, so I thought I’d sketch out a few basic ideas about how I’ve been approaching it over the last decade or so. Ideally I’d like to circle back around to this and better document more of the individual aspects or maybe even make a short video, but for now this will hopefully suffice to add to the conversation Michael has started.
Lots of good insights in the responses. One thing stands out: this is a real pain point for many, & I don’t think anyone feels like they’ve nailed it (or how they organize information in general). It’d be great to have more ideas added to the thread! https://t.co/6KfhO5aVU3
How do people organize their reading? Perennially frustrated by this. I want one system that lets me trivially add books, papers, webpages, etc, re-organize very easily, search & filter. What works for you?
Keep in mind that this is an evolving system which I still haven’t completely perfected (and may never), but to a great extent it works relatively well and I still easily have the ability to modify and improve it.
Overall Structure
The first piece of the overarching puzzle is to have a general structure for finding, collecting, triaging, and then processing all of the data. I’ve essentially built a simple funnel system for collecting all the basic data in the quickest manner possible. With the basics down, I can later skim through various portions to pick out the things I think are the most valuable and move them along to the next step. Ultimately I end up reading the best pieces on which I make copious notes and highlights. I’m still slowly trying to perfect the system for best keeping all this additional data as well.
Since I’ve seen so many apps and websites come and go over the years and lost lots of data to them, I far prefer to use my own personal website for doing a lot of the basic collection, particularly for online material. Toward this end, I use a variety of web services, RSS feeds, and bookmarklets to quickly accumulate the important pieces into my personal website which I use like a modern day commonplace book.
Collecting
In general, I’ve been using the Inoreader feed reader to track a large variety of RSS feeds from various clearinghouse sources (including things like ProQuest custom searches) down to individual researcher’s blogs as a means of quickly pulling in large amounts of research material. It’s one of the more flexible readers out there with a huge number of useful features including the ability to subscribe to OPML files, which many readers don’t support.
As a simple example arXiv.org has an RSS feed for the topic of “information theory” at http://arxiv.org/rss/math.IT which I subscribe to. I can quickly browse through the feed and based on titles and/or abstracts, I can quickly “star” the items I find most interesting within the reader. I have a custom recipe set up for the IFTTT.com service that pulls in all these starred articles and creates new posts for them on my WordPress blog. To these posts I can add a variety of metadata including top level categories and lower level tags in addition to other additional metadata I’m interested in.
I also have similar incoming funnel entry points via many other web services as well. So on platforms like Twitter, I also have similar workflows that allow me to use services like IFTTT.com or Zapier to push the URLs easily to my website. I can quickly “like” a tweet and a background process will suck that tweet and any URLs within it into my system for future processing. This type of workflow extends to a variety of sites where I might consume potential material I want to read and process. (Think academic social services like Mendeley, Academia.com, Diigo, or even less academic ones like Twitter, LinkedIn, etc.) Many of these services often have storage ability and also have simple browser bookmarklets that allow me to add material to them. So with a quick click, it’s saved to the service and then automatically ported into my website almost without friction.
My WordPress-based site uses the Post Kinds Plugin which takes incoming website URLs and does a very solid job of parsing those pages to extract much of the primary metadata I’d like to have without requiring a lot of work. For well structured web pages, it’ll pull in the page title, authors, date published, date updated, synopsis of the page, categories and tags, and other bits of data automatically. All these fields are also editable and searchable. Further, the plugin allows me to configure simple browser bookmarklets so that with a simple click on a web page, I can pull its URL and associated metadata into my website almost instantaneously. I can then add a note or two about what made me interested in the piece and save it for later.
Note here, that I’m usually more interested in saving material for later as quickly as I possibly can. In this part of the process, I’m rarely ever interested in reading anything immediately. I’m most interested in finding it, collecting it for later, and moving on to the next thing. This is also highly useful for things I find during my busy day that I can’t immediately find time for at the moment.
At regular intervals during the week I’ll sit down for an hour or two to triage all the papers and material I’ve been sucking into my website. This typically involves reading through lots of abstracts in a bit more detail to better figure out what I want to read now and what I’d like to read at a later date. I can delete out the irrelevant material if I choose, or I can add follow up dates to custom fields for later reminders.
Slowly but surely I’m funneling down a tremendous amount of potential material into a smaller, more manageable amount that I’m truly interested in reading on a more in-depth basis.
Document storage
Calibre with GoodReads sync
Even for things I’ve winnowed down, there is still a relatively large amount of material, much of it I’ll want to save and personally archive. For a lot of this function I rely on the free multi-platform desktop application Calibre. It’s essentially an iTunes-like interface, but it’s built specifically for e-books and other documents.
Within it I maintain a small handful of libraries. One for personal e-books, one for research related textbooks/e-books, and another for journal articles. It has a very solid interface and is extremely flexible in terms of configuration and customization. You can create a large number of custom libraries and create your own searchable and sort-able fields with a huge variety of metadata. It often does a reasonable job of importing e-books, .pdf files, and other digital media and parsing out their meta data which prevents one from needing to do some of that work manually. With some well maintained metadata, one can very quickly search and sort a huge amount of documents as well as quickly prioritize them for action. Additionally, the system does a pretty solid job of converting files from one format to another, so that things like converting an .epub file into a .mobi format for Kindle are automatic.
Calibre stores the physical documents either in local computer storage, or even better, in the cloud using any of a variety of services including Dropbox, OneDrive, etc. so that one can keep one’s documents in the cloud and view them from a variety of locations (home, work, travel, tablet, etc.)
I’ve been a very heavy user of GoodReads.com for years to bookmark and organize my physical and e-book library and anti-libraries. Calibre has an exceptional plugin for GoodReads that syncs data across the two. This (and a few other plugins) are exceptionally good at pulling in missing metadata to minimize the amount that must be done via hand, which can be tedious.
Within Calibre I can manage my physical books, e-books, journal articles, and a huge variety of other document related forms and formats. I can also use it to further triage and order the things I intend to read and order them to the nth degree. My current Calibre libraries have over 10,000 documents in them including over 2,500 textbooks as well as records of most of my 1,000+ physical books. Calibre can also be used to add document data that one would like to ultimately acquire the actual documents, but currently don’t have access to.
BibTeX and reference management
In addition to everything else Calibre also has some well customized pieces for dovetailing all its metadata as a reference management system. It’ll allow one to export data in a variety of formats for document publishing and reference management including BibTex formats amongst many others.
Reading, Annotations, Highlights
Once I’ve winnowed down the material I’m interested in it’s time to start actually reading. I’ll often use Calibre to directly send my documents to my Kindle or other e-reading device, but one can also read them on one’s desktop with a variety of readers, or even from within Calibre itself. With a click or two, I can automatically email documents to my Kindle and Calibre will also auto-format them appropriately before doing so.
Typically I’ll send them to my Kindle which allows me a variety of easy methods for adding highlights and marginalia. Sometimes I’ll read .pdf files via desktop and use Adobe to add highlights and marginalia as well. When I’m done with a .pdf file, I’ll just resave it (with all the additions) back into my Calibre library.
Exporting highlights/marginalia to my website
For Kindle related documents, once I’m finished, I’ll use direct text file export or tools like clippings.io to export my highlights and marginalia for a particular text into simple HTML and import it into my website system along with all my other data. I’ve briefly written about some of this before, though I ought to better document it. All of this then becomes very easily searchable and sort-able for future potential use as well.
Here’s an example of some public notes, highlights, and other marginalia I’ve posted in the past.
Synthesis
Eventually, over time, I’ve built up a huge amount of research related data in my personal online commonplace book that is highly searchable and sortable! I also have the option to make these posts and pages public, private, or even password protected. I can create accounts on my site for collaborators to use and view private material that isn’t publicly available. I can also share posts via social media and use standards like webmention and tools like brid.gy so that comments and interactions with these pieces on platforms like Facebook, Twitter, Google+, and others is imported back to the relevant portions of my site as comments. (I’m doing it with this post, so feel free to try it out yourself by commenting on one of the syndicated copies.)
Now when I’m ready to begin writing something about what I’ve read, I’ve got all the relevant pieces, notes, and metadata in one centralized location on my website. Synthesis becomes much easier. I can even have open drafts of things as I’m reading and begin laying things out there directly if I choose. Because it’s all stored online, it’s imminently available from almost anywhere I can connect to the web. As an example, I used a few portions of this workflow to actually write this post.
Continued work
Naturally, not all of this is static and it continues to improve and evolve over time. In particular, I’m doing continued work on my personal website so that I’m able to own as much of the workflow and data there. Ideally I’d love to have all of the Calibre related piece on my website as well.
Earlier this week I even had conversations about creating new post types on my website related to things that I want to read to potentially better display and document them explicitly. When I can I try to document some of these pieces either here on my own website or on various places on the IndieWeb wiki. In fact, the IndieWeb for Education page might be a good place to start browsing for those interested.
One of the added benefits of having a lot of this data on my own website is that it not only serves as my research/data platform, but it also has the traditional ability to serve as a publishing and distribution platform!
Currently, I’m doing most of my research related work in private or draft form on the back end of my website, so it’s not always publicly available, though I often think I should make more of it public for the value of the aggregation nature it has as well as the benefit it might provide to improving scientific communication. Just think, if you were interested in some of the obscure topics I am and you could have a pre-curated RSS feed of all the things I’ve filtered through piped into your own system… now multiply this across hundreds of thousands of other scientists? Michael Nielsen posts some useful things to his Twitter feed and his website, but what I wouldn’t give to see far more of who and what he’s following, bookmarking, and actually reading? While many might find these minutiae tedious, I guarantee that people in his associated fields would find some serious value in it.
I’ve tried hundreds of other apps and tools over the years, but more often than not, they only cover a small fraction of the necessary moving pieces within a much larger moving apparatus that a working researcher and writer requires. This often means that one is often using dozens of specialized tools upon which there’s a huge duplication of data efforts. It also presumes these tools will be around for more than a few years and allow easy import/export of one’s hard fought for data and time invested in using them.
If you’re aware of something interesting in this space that might be useful, I’m happy to take a look at it. Even if I might not use the service itself, perhaps it’s got a piece of functionality that I can recreate into my own site and workflow somehow?
If you’d like help in building and fleshing out a system similar to the one I’ve outlined above, I’m happy to help do that too.
I’ve apparently just posted my 3,000th public post on my personal website! It feels good to be owning more and more of the data I post online instead of just giving it to social media silos.
This week, using the magic of open web standards, I was able to write an issue post on my own website, automatically syndicate a copy of it to GitHub, and later automatically receive a reply to the copy on GitHub back to my original post as a comment there. This gives my personal website a means of doing two way communication with GitHub.
This functionality is another in a long line of content types my website is able to support so that I’m able to own my own content, yet still be able to interact with people on other websites and social media services. Given the number of social sites I’ve seen disappear over the years (often taking my content with them), this functionality gives me a tremendously larger amount of control and ownership over my web presence and identity while still allowing me to easily communicate with others.
In this post I wanted to briefly sketch what I’ve done to enable this functionality, so others who are so inclined can follow along to do the same thing.
Setting up WordPress to syndicate to GitHub
I’ll presume as a first step that one has both a GitHub account and a self-hosted WordPress website, though the details will also broadly apply to just about any content management system out there that supports the web standards mentioned.
Register your GitHub account and your website with Bridgy
Ryan Barrett runs a fantastic free open sourced service called Bridgy. To use it you’ll need the microformat rel=“me” links on both your GitHub account and your website’s homepage that point at each other. GitHub will do most of the work on its side for you simply by adding the URL of your website to the URL field for your GitHub account at https://github.com/settings/profile. Next on your website’s homepage, you’ll want to add a corresponding rel=“me” link from your website to your GitHub account.
In my case, I have a simple widget on my homepage with roughly the following link: <a href="https://github.com/username">GitHub</a>
in which I’ve replaced ‘username’ with my own GitHub username. There are a variety of other ways to add a rel=“me” link to your webpage, some of which are documented on the IndieWeb wiki.
Now you can go to Brid.gy and under “Connect your accounts” click on the GitHub button. This will prompt you to sign into GitHub via oAuth if you’re not already logged into the site. If you are already signed in, Brid.gy will check that the rel=“me” links on both your site and your GitHub account reciprocally point at each other and allow you to begin using the service to pull replies to your posts on GitHub back to your website.
To allow Brid.gy to publish to GitHub on your behalf (via webmention, which we’ll set up shortly), click on the “Publish” button.
Install the Webmention Plugin
The underlying technology that allows the Bridgy service to both publish on one’s behalf as well as for the replies from GitHub to come back to one’s site is an open web standard known as Webmention. WordPress can quickly and easily support this standard with the simple Webmention plugin that can be downloaded and activated on one’s site without any additional configuration.
For replies coming back from GitHub to one’s site it’s also recommended that one also install and activate the Semantic Linkbacks Plugin which also doesn’t require any configuration. This plugin provides better integration and UI features in the comments section of one’s website.
Install Post Kinds Plugin
The Post Kinds Plugin is somewhat similar to WordPress’s Post Formats core functionality, it just goes the extra mile to support a broader array of post types with the appropriate meta data and semantic markup for interacting with Bridgy, other web parsers, and readers.
Download the plugin, activate it, and in the plugin’s settings page enable the “Issue” kind. For more details on using it, I’ve written about this plugin in relative detail in the past.
Install Bridgy Publish Plugin
One can just as easily install the Bridgy Publish Plugin for WordPress and activate it. This will add a meta box to one’s publishing dashboard that, after a quick configuration of which social media silos one wishes to support, will allow one to click a quick checkbox to automatically syndicate their posts.
Install the Syndication Links Plugin
The Syndication Links plugin is also a quick install and activate process. You can modify the settings to allow a variety of ways to display your syndication links (or not) on your website if you wish.
This plugin will provide the Bridgy Publish Plugin a place to indicate the permalink of where your syndicated content lives on GitHub. The Bridgy service will use this permalink to match up the original content on your website and the copy on GitHub so that when there are replies, it will know which post to send those replies to as comments which will then live on your own website.
Post away
You should now be ready to write your first issue on your website, cross post it to GitHub (a process known in IndieWeb parlance as POSSE), and receive any replies to your GitHub issue as comments back to your own website.
Create a new post.
In the “Kinds” meta box, choose the “Issue” option.
Kinds meta box with “Issue” option chosen.
Type in a title for the issue in the “Title” field.
In the “Response Properties” meta box, put the permalink URL of the Github repopository for which you’re creating an issue. The plugin should automatically process the URL and import the repository name and details.
The “Response Properties” meta box.
In the primary editor, type up any details for the issue as you would on GitHub in their comment box. You can include a relatively wide variety of custom symbols and raw html including
and with code samples which will cross-post and render properly.
In the GitHub meta box, select the GitHub option. You can optionally select other boxes if you’re also syndicating your content to other services as well. See the documentation for Bridgy and the plugin for how to do this.
Bridgy Publish meta box with GitHub chosen.
Optionally set any additional metadata for your post (tags, categories, etc.) as necessary.
Publish your post.
On publication, your issue should be automatically filed to the issue queue of the appropriate GitHub repo and include a link back to your original (if selected). Your post should receive the syndicated permalink of the issue on GitHub and be displayed (depending on your settings) at the bottom of your post.
Syndication Links Plugin will display the location of your syndicated copies at the bottom of your post.
When Bridgy detects future interactions with the copy of your post on GitHub, it will copy them and send them to your original post as a webmention so that they can be displayed as comments there.
An example of a comment sent via webmention from GitHub via Brid.gy. It includes a permalink to the comment as well as a link to the GitHub user’s profile and their avatar.
If you frequently create issues on GitHub like this you might want a slightly faster way of posting. Toward that end, I’ve previously sketched out how to create browser bookmarklets that will allow you one click post creation from a particular GitHub repo to speed things along. Be sure to change the base URL of your website and include the correct bookmarklet type of “issue” in the code.
The Post Kinds plugin will also conveniently provide you with an archive of all your past Issue posts at the URL http://example.com/kind/issue/, where you can replace example.com with your own website. Adding feed/ to the end of that URL provides an RSS feed link as well. Post Kinds will also let you choose the “Reply” option instead of “Issue” to create and own your own replies to GitHub issues while still syndicating them in a similar manner and receive replies back.
Other options
Given the general set up of the variety of IndieWeb-based tools, there are a multitude of other ways one can also accomplish this workflow (both on WordPress as well as with an infinity of other CMSes). The outline I’ve provided here is one of the quickest methods for beginners that will allow a relatively high level of automation and almost no manual work.
One doesn’t necessarily need to use the Post Kinds Plugin, but could manually insert all the requisite HTML into their post editor to accomplish the post side of things via webmention. (One also has the option to manually syndicate the content to GitHub by cutting and pasting it as well.) If doing things manually this way is desired, then one will need to also manually provide a link to the syndicated post on GitHub into their original so that Bridgy can match up the copy and the original to send the replies via webmention.
If you’ve followed many of these broad steps, you’ve given already given yourself an incredibly strong IndieWeb-based WordPress installation. With a minimal amount of small modifications you can also use it to dovetail your website with other social services like Twitter, Facebook, Flickr, Instagram, Google+ and many others. Why not take a quick look around on the IndieWeb wiki to see what other magic you can perform with your website!
I’ve documented many of my experiments, including this one, in a collection of posts for reference.
Help
If you have questions or problems, feel free to comment below or via webmention using your own website. You can also find a broad array of help with these plugins, services, and many other pieces of IndieWeb technology in their online chat rooms.
I don’t post “notes” to Facebook often, but I’d noticed a few weeks ago that several pieces I’d published like this a while back were apparently unpublished by the platform. I hadn’t seen or heard anything from Facebook about them being unpublished or having issues, so I didn’t realize the problem until I randomly stumbled back across my notes page.
They did have a piece of UI to indicate that I wanted to contest and republish them, so I clicked on it. Apparently this puts these notes into some type of limbo “review” process, but it’s been a few weeks now and there’s no response about either of them. They’re still both sitting unseen in my dashboard with sad notes above them saying:
There is no real indication if they’ll ever come back online. Currently my only option is to delete them. There’s also no indication, clear or otherwise, of which community standard they may have violated.
I can’t imagine how either of the posts may have run afoul of their community standards, or why “notes” in particular seem to be more prone to this sort of censorship in comparison with typical status updates. I’m curious if others have had this same experience?
We’re reviewing these posts against our Community Standards.
This is just another excellent example of why one shouldn’t trust third parties over which you have no control to publish your content on the web. Fortunately I’ve got my own website with the original versions of these posts [1][2] that are freely readable. If you’ve experienced this or other pernicious problems in social media, I recommend you take a look at the helpful IndieWeb community which has some excellent ideas and lots of help for re-exerting control over your online presence.
Notes Functionality
Notes on Facebook were an early 2009 era attempt for Facebook to have more blog-like content and included a rather clean posting interface, not un-reminiscent of Medium’s interface, that also allowed one to include images and even hyperlinks into pages.
The note post type has long since fallen by the wayside and I rarely, if ever, come across people using it anymore in the wild despite the fact that it’s a richer experience than traditional status updates. I suspect the Facebook black box algorithm doesn’t encourage its use. I might posit that it’s not encouraged as unlike most Facebook functionality, hyperlinks in notes on desktop browsers physically take one out of the Facebook experience and into new windows!
The majority of notes about me are spammy chain mail posts like “25 Random Things About Me”, which also helpfully included written instructions for how to actually use notes.
25 Random Things About Me
Rules: Once you’ve been tagged, you are supposed to write a note with 25 random things, facts, habits, or goals about you. At the end, choose 25 people to be tagged. You have to tag the person who tagged you. If I tagged you, it’s because I want to know more about you.
(To do this, go to “notes” under tabs on your profile page, paste these instructions in the body of the note, type your 25 random things, tag 25 people (in the right hand corner of the app) then click publish.)
Most of my published notes were experiments in syndicating my content from my own blog to Facebook (via POSSE). At the time, the engagement didn’t seem much different than posting raw text as status updates, so I abandoned it. Perhaps I’ll try again with this post to see what happens? I did rather like the ability to actually have links to content and other resources in my posts there.
Since the old Lanyrd site was back up over the weekend, I went in and saved all of the old data I wanted from it before it decided to shut down again (there is no news on when this may happen). Sadly there is no direct export, but I was able to save pages individually and/or save them to the Internet Archive.
One thing we very much believe in is that you should own your own data. As such, we didn’t want to just suck your data into Notist and leave it at that. Instead, we’ve built a tool that gives you access to the content as HTML and JSON, ready for you to take away today.
Lanyrd is currently up, let us grab your data for import into Notist! https://t.co/QdYsSKIF1L
We really loved Lanyrd as a site for logging the events and conferences we were attending and speaking it. Worried that it might go away, we’ve fast-tracked a tool to help you grab your data.
Today I was reminded while thinking about Disqus that I had an Intense Debate account from April 23, 2009. Apparently it’s still functioning all these years later–possibly as a result of their purchase by Automattic in 2008. Not that there was much there, but I took a few minutes and exported out all my data and now own it here on my site.
One of the interesting parts was that it featured a comment about Twitter pulling the rug out from underneath developers–an event that foreshadowed even more of the same in the coming years as well as a conversation about the gamification of follower accounts, something which has gotten us into a sad state of affairs today nearly a decade later. Apparently while they tried to cap follower accounts, their early efforts just didn’t go far enough to help the civility of the platform.
For a quite a while I’ve been thinking about writing a book about the IndieWeb to provide a broader overview of what it is philosophically, how it works, how its community functions, and most specifically how the average person can more easily become a part of it.
Back in January Timo Reitnauer wrote Let’s Make 2017 The Year of the Indie Web. I agree wholehearted with the sentiment of his title and have been personally wanting to do something specific to make it a reality. With the changes I’ve seen in the internet over the past 22 years, and changes specifically in the last year, we certainly need it now more than ever.
In large part, I’ve been inspired by the huge number of diverse and big-hearted developers who are an active part of the growing community, but specifically today I came across a note by Doc Searls, an email about the upcoming NaNoWriMo (National Novel Writing Month), and then a reminder about the 100 Days of IndieWeb project. This confluence of events is clearly my tipping point.
As a result, I’m making my 2018 IndieWeb resolution early. For the month of November, as part of NaNoWriMo, I’m going to endeavor to lovingly craft together a string of about 2,000 words a day on the topic of the IndieWeb to create a book geared toward helping non-developers (ie. Generation 2 and Generation 3 people) more easily own their online identities and content.
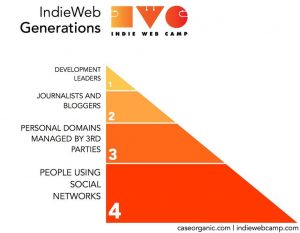
IndieWeb Generations Diagram by Amber Case (Caseorganic.com) as depicted on the IndieWeb Wiki
Over the past year, surely I’ve read, written about, or interacted with the IndieWeb community concretely in one way or another on at least 70 days. This sprint of 30 days should round out a 100 days project. To be honest, I haven’t necessarily posted about each of these interactions on my own site nor are they necessarily visible changes to my site, so it may not follow the exact requirements of the 100 Days of IndieWeb, but it follows the spirit of the creator idea with the hopes that the publicly visible result is ever more people adopting the principles of the movement for themselves.
I’ll focus the book primarily on how the average person can utilize the wealth of off-the-shelf tools of the WordPress content management system and its community–naturally with mentions of other easy-to-use platforms like Known and Micro.blog sprinkled throughout–to own their own domain, own their content, and better and more freely communicate with others online.
If you haven’t heard about the movement before, I’ll direct you to my article An Introduction to the IndieWeb, portions of which will surely inform the introduction of the book.
If you’ve recently joined the IndieWeb, I’d certainly love to hear your thoughts and stories about how you came to it, why you joined, and what the most troublesome parts have been so I can help direct people through them more easily–at least until there are a plurality of one-click solutions to let everyone IndieWeb-ify themselves online.
As a publisher who realizes the value of starting a PR campaign to support the resultant book, I’m also curious to hear thoughts about potentially launching a crowdfunding campaign to support the modest costs of the book, with profits (if any) going toward supporting the IndieWeb community.
I’m happy to entertain any other thoughts or considerations people have, so feel free to reply in the comments below, or better yet, reply on your own site and send me a webmention.