Evolutionary biology is a rapidly changing field, confronted to many societal problems of increasing importance: impact of global changes, emerging epidemics, antibiotic resistant bacteria… As a consequence, a number of new problematics have appeared over the last decade, challenging the existing mathematical models. There exists thus a demand in the biology community for new mathematical models allowing a qualitative or quantitative description of complex evolution problems. In particular, in the societal problems mentioned above, evolution is often interacting with phenomena of a different nature: interaction with other organisms, spatial dynamics, age structure, invasion processes, time/space heterogeneous environment… The development of mathematical models able to deal with those complex interactions is an ambitious task. Evolutionary biology is interested in the evolution of species. This process is a combination of several phenomena, some occurring at the individual level (e.g. mutations), others at the level of the entire population (competition for resources), often consisting of a very large number of individuals. the presence of very different scales is indeed at the core of theoretical evolutionary biology, and at the origin of many of the difficulties that biologists are facing. The development of new mathematical models thus requires a joint work of three different communities of researchers: specialists of partial differential equations, specialists of probability theory, and theoretical biologists. The goal of this workshop is to gather researchers from each of these communities, currently working on close problematics. Those communities have usually few interactions, and this meeting would give them the opportunity to discuss and work around a few biological thematics that are especially challenging mathematically, and play a crucial role for biological applications.
The role of a spatial structure in models for evolution: The introduction of a spatial structure in evolutionary biology models is often challenging. It is however well known that local adaptation is frequent in nature: field data show that the phenotypes of a given species change considerably across its range. The spatial dynamics of a population can also have a deep impact on its evolution. Assessing e.g. the impact of global changes on species requires the development of robust mathematical models for spatially structured populations.
The first type of models used by theoretical biologists for this type of problems are IBM (Individual Based Models), which describe the evolution of a finite number of individuals, characterized by their position and a phenotype. The mathematical analysis of IBM in spatially homogeneous situations has provided several methods that have been successful in the theoretical biology community (see the theory of Adaptive Dynamics). On the contrary, very few results exist so far on the qualitative properties of such models for spatially structured populations.
The second class of mathematical approach for this type of problem is based on ”infinite dimensional” reaction-diffusion: the population is structured by a continuous phenotypic trait, that affects its ability to disperse (diffusion), or to reproduce (reaction). This type of model can be obtained as a large population limit of IBM. The main difficulty of these models (in the simpler case of asexual populations) is the term modeling the competition from resources, that appears as a non local competition term. This term prevents the use of classical reaction diffusion tools such as the comparison principle and sliding methods. Recently, promising progress has been made, based on tools from elliptic equations and/or Hamilton-Jacobi equations. The effects of small populations can however not be observed on such models. The extension of these models and methods to include these effects will be discussed during the workshop.
Eco-evolution models for sexual populations:An essential question already stated by Darwin and Fisher and which stays for the moment without answer (although it continues to intrigue the evolutionary biologists) is: ”Why does sexual reproduction maintain?” Indeed this reproduction way is very costly since it implies a large number of gametes, the mating and the choice of a compatible partner. During the meiosis phasis, half of the genetical information is lost. Moreover, the males have to be fed and during the sexual mating, individual are easy preys for predators. A partial answer is that recombination plays a main role by better eliminating the deleterious mutations and by increasing the diversity. Nevertheless, this theory is not completely satisfying and many researches are devoted to understanding evolution of sexual populations and comparison between asexual and sexual reproduction. Several models exist to model the influence of sexual reproduction on evolving species. The difficulty compared to asexual populations is that a detailed description of the genetic basis of phenotypes is required, and in particular include recombinations. For sexual populations, recombination plays a main role and it is essential to understand. All models require strong biological simplifications, the development of relevant mathematical methods for such mechanisms then requires a joint work of mathematicians and biologists. This workshop will be an opportunity to set up such collaborations.
The first type of model considers a small number of diploid loci (typically one locus and two alleles), while the rest of the genome is considered as fixed. One can then define the fitness of every combination of alleles. While allowing the modeling of specific sexual effects (such as dominant/recessive alleles), this approach neglects the rest of the genome (and it is known that phenotypes are typically influenced by a large number of loci). An opposite approach is to consider a large number of loci, each locus having a small and additive impact on the considered phenotype. This approach then neglects many microscopic phenomena (epistasis, dominant/recessive alleles…), but allows the derivation of a deterministic model, called the infinitesimal model, in the case of a large population. The construction of a good mathematical framework for intermediate situation would be an important step forward.
The evolution of recombination and sex is very sensitive to the interaction between several evolutionary forces (selection, migration, genetic drift…). Modeling these interactions is particularly challenging and our understanding of the recombination evolution is often limited by strong assumptions regarding demography, the relative strength of these different evolutionary forces, the lack of spatial structure… The development of a more general theoretical framework based on new mathematical developments would be particularly valuable.
Another problem, that has received little attention so far and is worth addressing, is the modeling of the genetic material exchanges in asexual population. This phenomena is frequent in micro-organisms : horizontal gene transfers in bacteria, reassortment or recombination in viruses. These phenomena share some features with sexual reproduction. It would be interesting to see if the effect of this phenomena can be seen as a perturbation of existing asexual models. This would in particular be interesting in spatially structured populations (e.g. viral epidemics), since the the mathematical analysis of spatially structured asexual populations is improving rapidly.
Modeling in evolutionary epidemiology: Mathematical epidemiology has been developing since more than a century ago. Yet, the integration of population genetics phenomena to epidemiology is relatively recent. Microbial pathogens (bacteria and viruses) are particularly interesting organisms because their short generation times and large mutation rates allow them to adapt relatively fast to changing environments. As a consequence, ecological (demography) and evolutionary (population genetics) processes often occur at the same pace. This raises many interesting problems.
A first challenge is the modeling of the spatial dynamics of an epidemics. The parasites can evolve during the epidemics of a new host population, either to adapt to a heterogeneous environment, or because it will itself modify the environment as it invades. The applications of such studies are numerous: antibiotic management, agriculture… An aspect of this problem for which our workshop can bring a significant contribution (thanks to the diversity of its participants) is the evolution of the pathogen diversity. During the large expansion produced by an epidemics, there is a loss of diversity in the invading parasites, since most pathogens originate from a few parents. The development of mathematical models for those phenomena is challenging: only a small number of pathogens are present ahead of the epidemic front, while the number of parasites rapidly become very large after the infection. The interaction between a stochastic micro scale and a deterministic macro scale is apparent here, and deserves a rigorous mathematical analysis.
Another interesting phenomena is the effect of a sudden change of the environment on a population of pathogens. Examples of such situations are for instance the antibiotic treatment of an infected patients, or the transmission of a parasite to a new host species (transmission of the avian influenza to human beings, for instance). Related experiments are relatively easy to perform, and called evolutionary rescue experiments. So far, this question has received limited attention from the mathematical community. The key is to estimate the probability that a mutant well adapted to the new environment existed in the original population, or will appear soon after the environmental change. Interactions between biologists specialists of those questions and mathematicians should lead to new mathematical problems.
Isaac Chuang Professor of Electrical Engineering and Computer Science, and Professor of Physics MIT
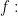 that it is differentiable in the complex sense. This condition is called holomorphicity, and it shapes most of the theory discussed in this book.
that it is differentiable in the complex sense. This condition is called holomorphicity, and it shapes most of the theory discussed in this book.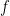 is holomorphic in
is holomorphic in 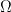 , then for appropriate closed paths in
, then for appropriate closed paths in 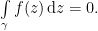
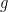 are holomorphic functions in
are holomorphic functions in  everywhere in
everywhere in 





